When you’re planning to move a workload to the cloud, whether public or private, you need to select the best instance size and volume types to meet your needs. Sounds obvious, but the process is anything but.
Toto, we’re not in the data center any more
When planning your on-premises infrastructure, you’re making capital investments in hardware and software licenses, so you need to design for the future. You want to deliberately overprovision, both to design for redundancy to minimize outages and for your future needs so you can support expected growth over the next term of some number of years. Once that infrastructure is in place, your costs are essentially the same whether you use some, most, or all of that capacity. The pay-for-what-you-use model in the cloud, however, requires you to fundamentally change your approach to planning and sizing (unless, of course, you don’t mind paying a whole lot of money right now for capacity that you don’t need right now). This means you have to shift the way you think about your workloads. There are three key steps you must take. And all along the way, there’s one very important thing to keep in mind: There’s no such thing as an average workload.
Step 1: Measure workload size
You need to understand what resources your workload is currently using in the data center so you can figure out what you need for it when you migrate it to the cloud. To do this, you need to collect data about workload behavior over time during peak business hours. Whether that’s two weeks or two months or some other time frame depends on your business, but you need a representative period to make the right sizing decisions. This is important, because there’s no such thing as an average workload.
Some tools will aggregate and/or sample the data to give you average utilization data, which can be highly deceptive. This can necessitate expensive adjustments during the pilot phase, which is one of the reasons why migrations often result in unnecessary costs. Consider the examples below:
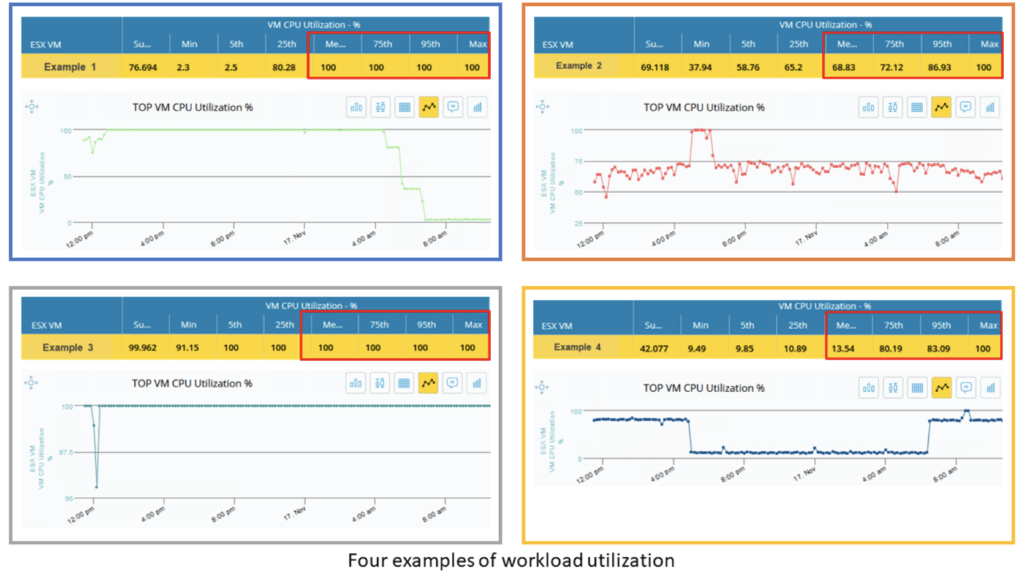
These four workloads clearly behave very differently from each other. If you were to average workloads 1 and 2, for example, they might end up looking the same, which would be misleading. And while each one reaches 100% CPU utilization at some point during the time series, workloads 1 and 3 are at 100% almost 100% of the time; workload 2 hits 100% for a short run; and workload 4 operates at around 10% half the time, going up to around 80% for the other half and peaking at 100% for only a brief period.
Based on this information, you probably have a pretty good idea for what you need to support workloads 1 and 3. But what about workloads 2 and 4? That’s where step 2 comes in, which is all about percentiles and purpose.
Step 2: Appraise workload objective
Consider workload 2. Unlike workloads 1 and 3 that are running at maximum in the 95th percentile, workload 2 is at 87% in the 95th percentile, which means that 95% of the values are below that 87% mark. You can size it to the peak, but then you’ll be paying for a level of capacity that’s only needed 5% of the time. Or you can size it to the 95th percentile level and face latency during that peak time. Let’s say the cost difference between the two options is $1 million. This is where you need to understand the purpose of that workload. Again, there’s no such thing as an average workload—each one needs to accomplish something specific for your organization. For instance, if it’s a backup application that starts at midnight and finishes at 2 a.m., is it acceptable for it to take a couple of extra hours? That’s a pretty easy yes. Another option for the backup application is to take advantage of the hibernate feature offered by CSPs which will further reduce cost. But if it’s a transactional server processing stock-price updates, that latency could cost you multiple millions. In that case, you probably do want to spend the extra $1 million and size to the maximum. Of course, not every decision will be as clear cut as these two examples. What if it’s a back-office application that supports several key functions? On to step 3.
Step 3: Evaluate your best-fit-for-purpose options
To make the optimal selection for any given workload, you need to understand your choices. The table below shows the costs for different potential sizing levels for workload 2.
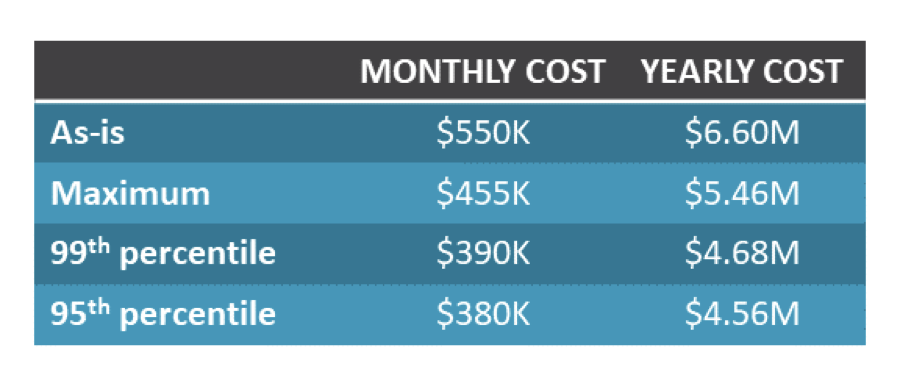
Note that “as-is” reflects the cost of replicating your on-premises capacity. While you probably would never want to do this, it can be useful information to have. Here you can see that even if you size to current maximum utilization, you’ll save $1.2M per year over “as-is”—and when you do need to expand, you can do so at that point. For the stock-price application that has no tolerance for latency, spending the extra $780K per year for maximum (vs. 99th percentile) is probably cost-justified. And for the backup application, the $900K you save by dropping down to the 95th percentile is a no-brainer. For the back-office application, however, while you may be able to tolerate a small amount of infrequent latency, for the most part you need to ensure good performance. In this case, sizing to the 99th percentile might be your best bet.
It is important to highlight that you want to leverage a platform that can provide you with at least four categories (as-is, peak maximum value, 99th percentile, and 95th percentile) for all dimensions—CPU MHz, memory utilization, read/write throughput/IOPS, and network receive/transmit. Otherwise, you will have an inaccurate and incomplete view.
Smarter planning delivers better results
When you’re buying a house, you don’t look for one that will meet the needs of the average family, you want one that meets the needs of your family. You don’t buy clothes to fit the average person, you buy them in your size and style. And it’s the same when you’re migrating your workloads to the cloud. When you plan smarter based on reality not averages, you can get the best performance, whatever that means for a particular workload, at the lowest cost.
Virtana: Not your average cloud migration partner
With Virtana Workload Placement, you can discover, map, and characterize your workloads, and then evaluate all of the cloud configuration options based on those characteristics, the associated costs, and your tolerance for latency/risk. With our AI, machine learning, and data-driven analytics combined with our deep understanding of your workloads running on premises, you can get your migration right the first time, every time while eliminating unexpected costs and performance degradation after migration. Try it for free
When you’re planning to move a workload to the cloud, whether public or private, you need to select the best instance size and volume types to meet your needs. Sounds obvious, but the process is anything but.

Ricardo Negrete


