Maximize Kubernetes Performance with Intelligent Observability
Eliminate blind spots, reduce noise, and optimize your containerized infrastructure with AI-powered insights.

95% Improvement in MTTR
AI-driven RCA and anomaly detection resolve issues faster than traditional monitoring tools. US-based manufacturing company

99.999% Uptime
Proactively avoid outages by catching issues before they escalate. West coast-based healthcare provider

30% Infrastructure Savings
Eliminate unnecessary overprovisioning and streamline capacity planning for maximum efficiency. UK-based financial institution
The Challenge: Observability in a Dynamic Kubernetes World
Modern containerized applications scale rapidly, spin up and down in seconds, and rely on complex interdependencies across clusters, environments, data centers, and clouds. Traditional monitoring tools struggle to provide real-time insights, leading to:
- Alert Overload – Too many signals with no clear root cause.
- Fragmented Data – Logs, metrics, traces, and configuration live in disconnected tools.
- Resource Waste – Over-provisioning drives up costs while under-allocation impacts performance.
To keep your Kubernetes applications running efficiently, you need intelligent observability that unifies data, automates analysis, and optimizes performance across your entire environment.
The Solution: Virtana’s AI-Powered Container Observability
Virtana delivers a unified, full-stack observability platform purpose-built for Kubernetes environments. With advanced AI, automated root cause analysis, and real-time visibility, you can eliminate performance blind spots, reduce alert noise, and optimize infrastructure and workload resource allocations.
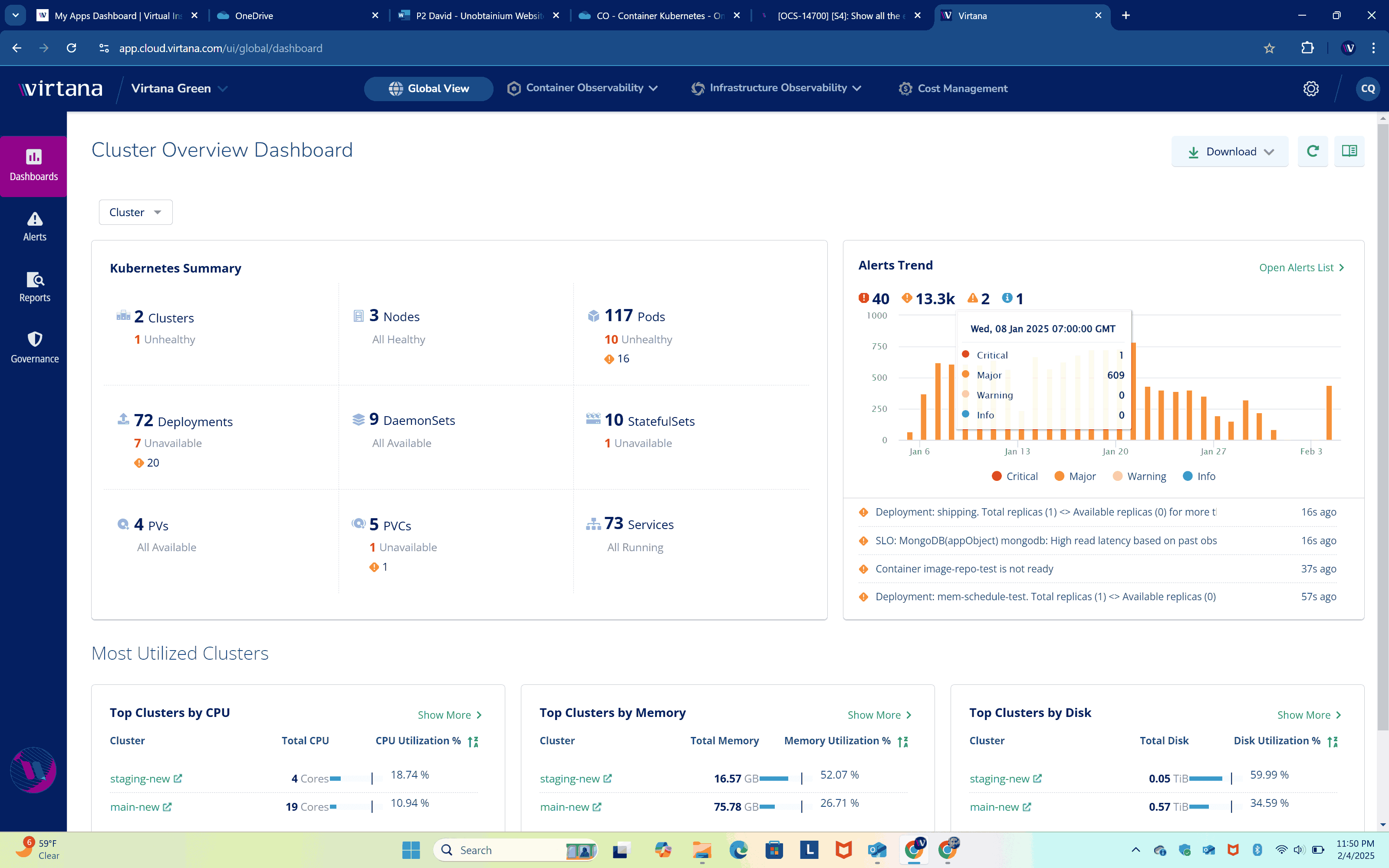
Unified Telemetry: End-to-End Visibility Across Kubernetes
Bring together logs, metrics, traces, and dependencies in a single pane of glass.
- Eliminate Data Silos – Correlate data across clusters, nodes, and applications for complete visibility.
- Accelerate Troubleshooting – Drill down from alerts to root cause in seconds.
- Reduce Complexity – No need for proprietary agents or manual data unification to operationalize.
AI-Driven Anomaly Detection: Proactive Health and Performance Insights
Detect issues before they impact users with AI and machine learning-powered alerts.
- Reduce Downtime – Identify performance deviations early and get automated root cause.
- Cut Through Noise – Stop chasing false positives with intelligent alerting and relationship-based noise reduction.
- Improve Resilience – Automatically learn what “normal” looks like and detect anomalies in real-time.
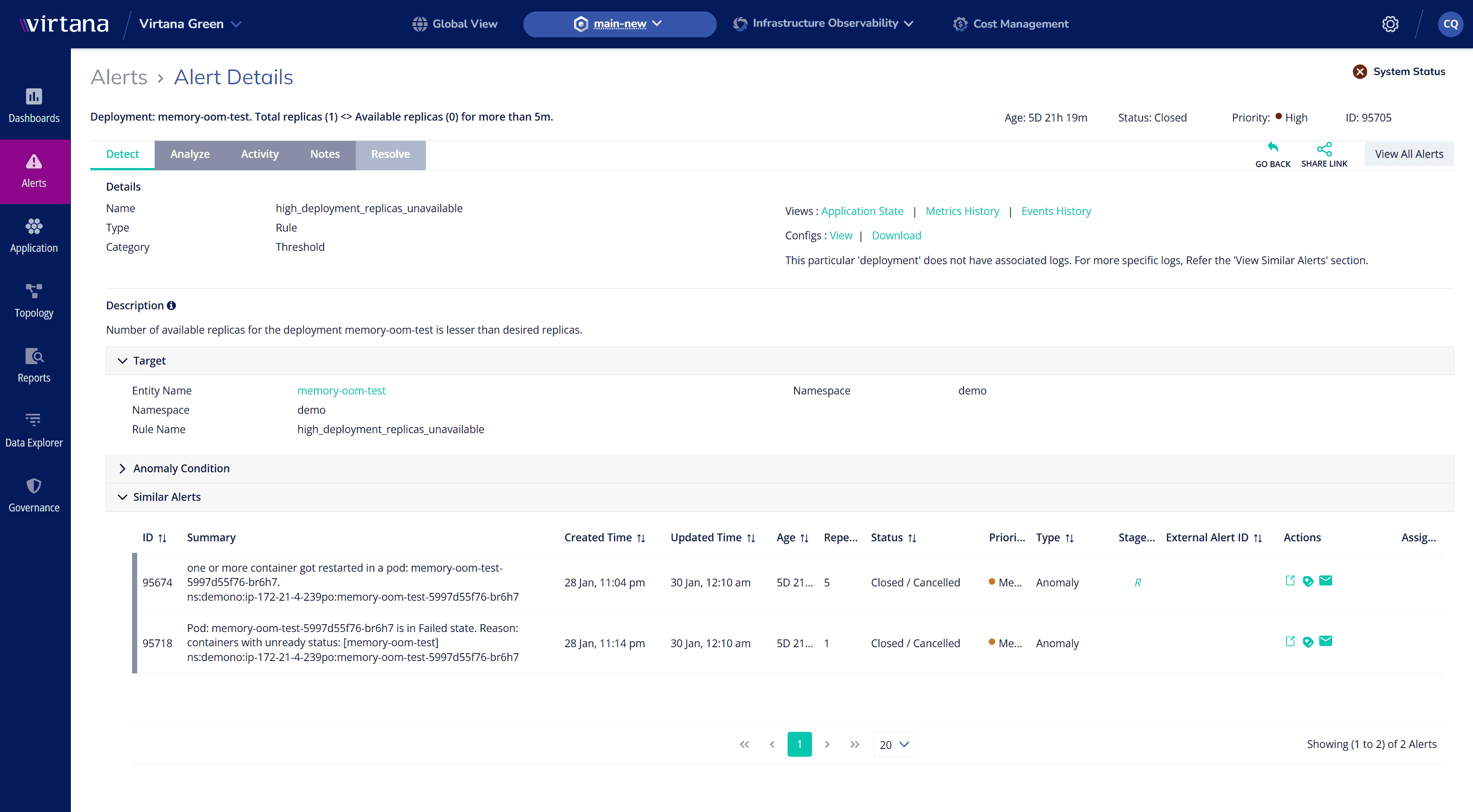
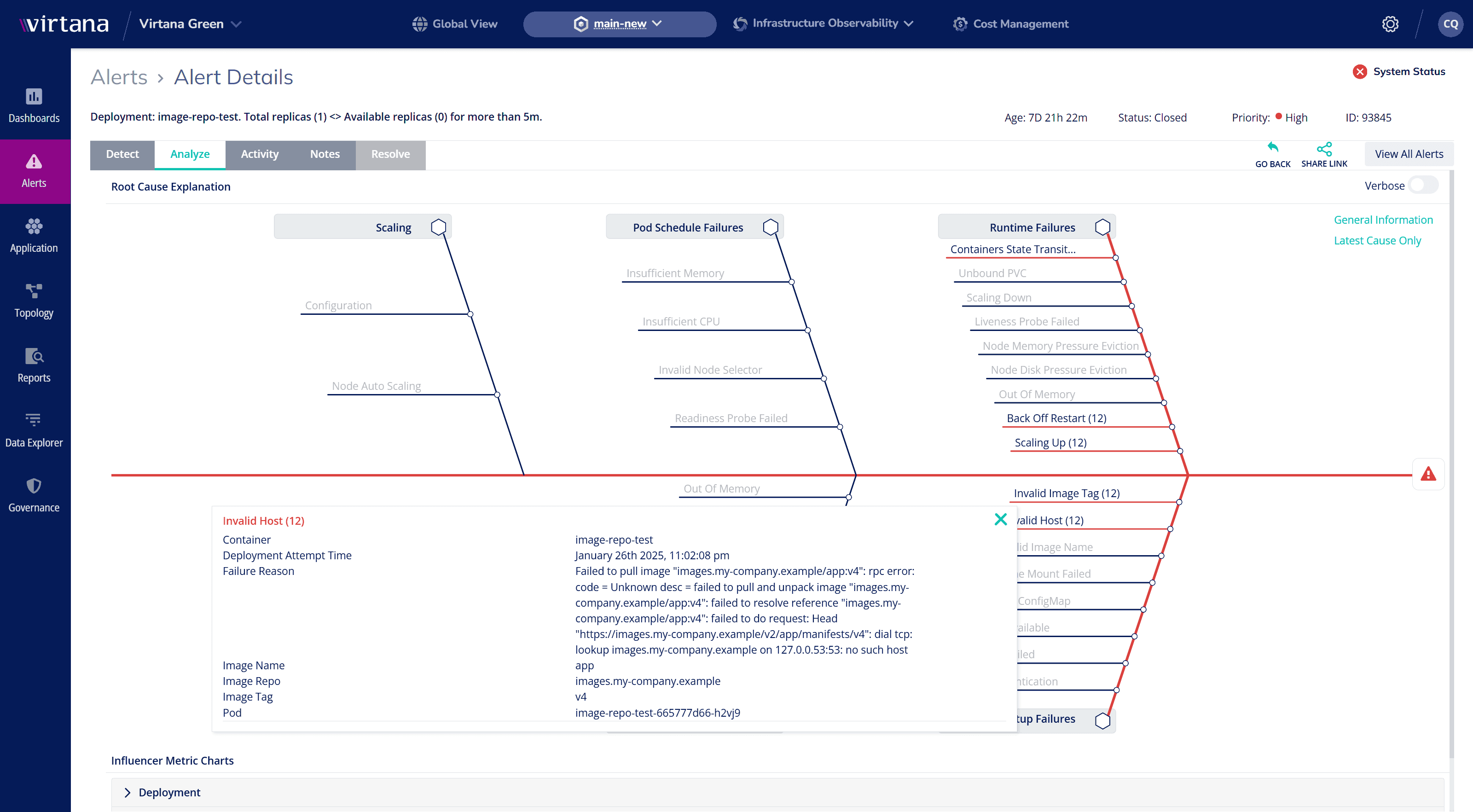
Automated Root Cause Analysis: Pinpoint Issues in Seconds
Let AI act as your expert, analyzing failures and identifying fixes instantly.
- Eliminate War Rooms – Get instant root cause insights without manual guesswork.
- Accelerate Resolution – Reduce MTTR with guided remediation.
- Improve Efficiency – Give time and cycles back to DevOps and SRE teams to focus on innovation.
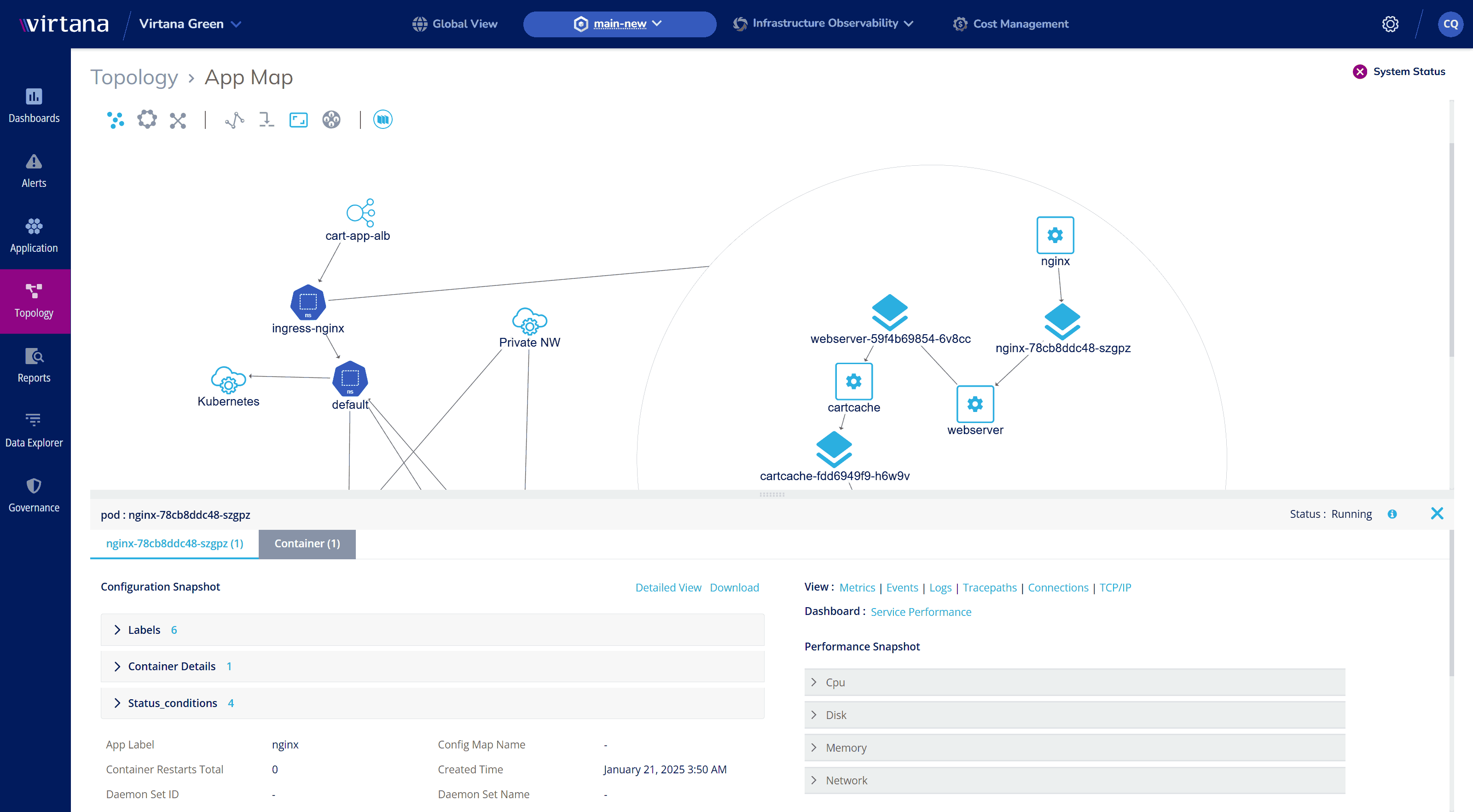
Kubernetes Resource Optimization: Maximize Efficiency, Right-Size your Clusters and Workloads
Stop over-provisioning / under-provisioning and ensure your containers get the right resources.
- Gain Global, Real-Time Insights – Continuously monitor workload utilization at the cluster, namespace, and resource levels across all your clusters to maximize performance and cost efficiency.
- Reduce Cloud Waste – Prevent unnecessary over-allocation and cut costs by 25% or more.
- Improve Performance – Ensure applications always have the resources they need.

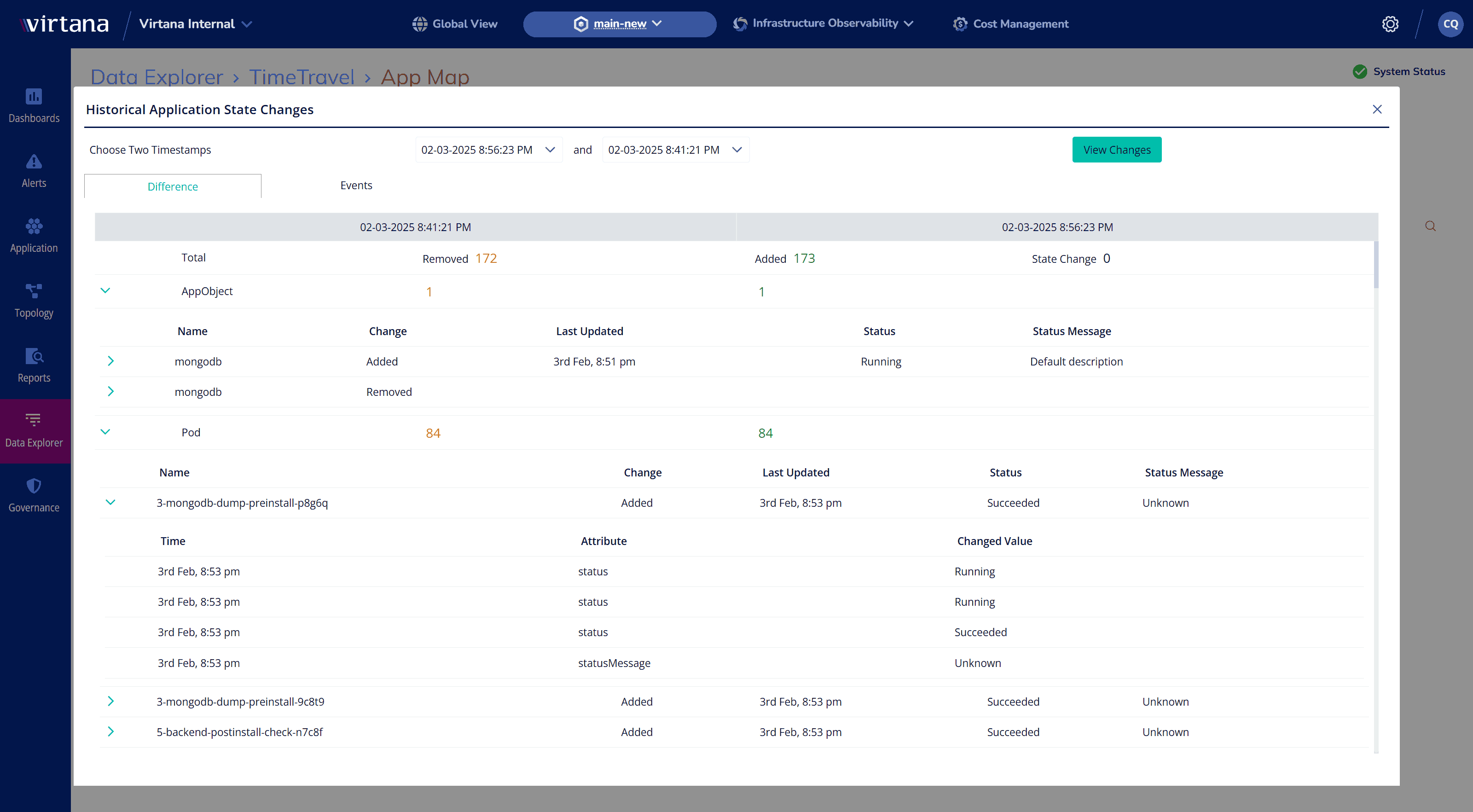
Time Travel for Forensics: Investigate Issues Even After They’re Gone
Look back in time at Kubernetes environments and analyze historical performance, health, and configuration.
- Pinpoint Past Failures – Investigate what happened—even if the workload no longer exists.
- Enhance Compliance & Auditing – Understand data flow and architectural changes to ensure best practices and data compliance.
- Track Historical Root Cause – Troubleshoot and identify causes with confidence using point-in-time insights into workload behavior.