Eliminate Server Blind Spots with Intelligent OS Observability
Monitor host performance, detect anomalies, and optimize workloads with AI-powered insights.

95% Improvement in MTTR
AI-driven RCA and anomaly detection resolve issues faster than traditional monitoring tools. US-based manufacturing company

99.999% Uptime
Proactively avoid outages by catching issues before they escalate. West coast-based healthcare provider

30% Infrastructure Savings
Eliminate unnecessary overprovisioning and streamline capacity planning for maximum efficiency. UK-based financial institution
The Challenge: Limited Visibility into OS & Server Performance
Your operating system and server infrastructure form the foundation of your applications. But without deep visibility, you face:
- Performance Bottlenecks – Unused capacity or overloaded resources slow down critical workloads.
- Alert Noise – Disconnected monitoring tools create fragmented insights, making RCA difficult.
- Scaling Challenges – Unclear resource utilization makes it hard to scale efficiently.
Traditional monitoring solutions often fall short, lacking contextual insights and automated analysis to help IT teams proactively manage infrastructure health.
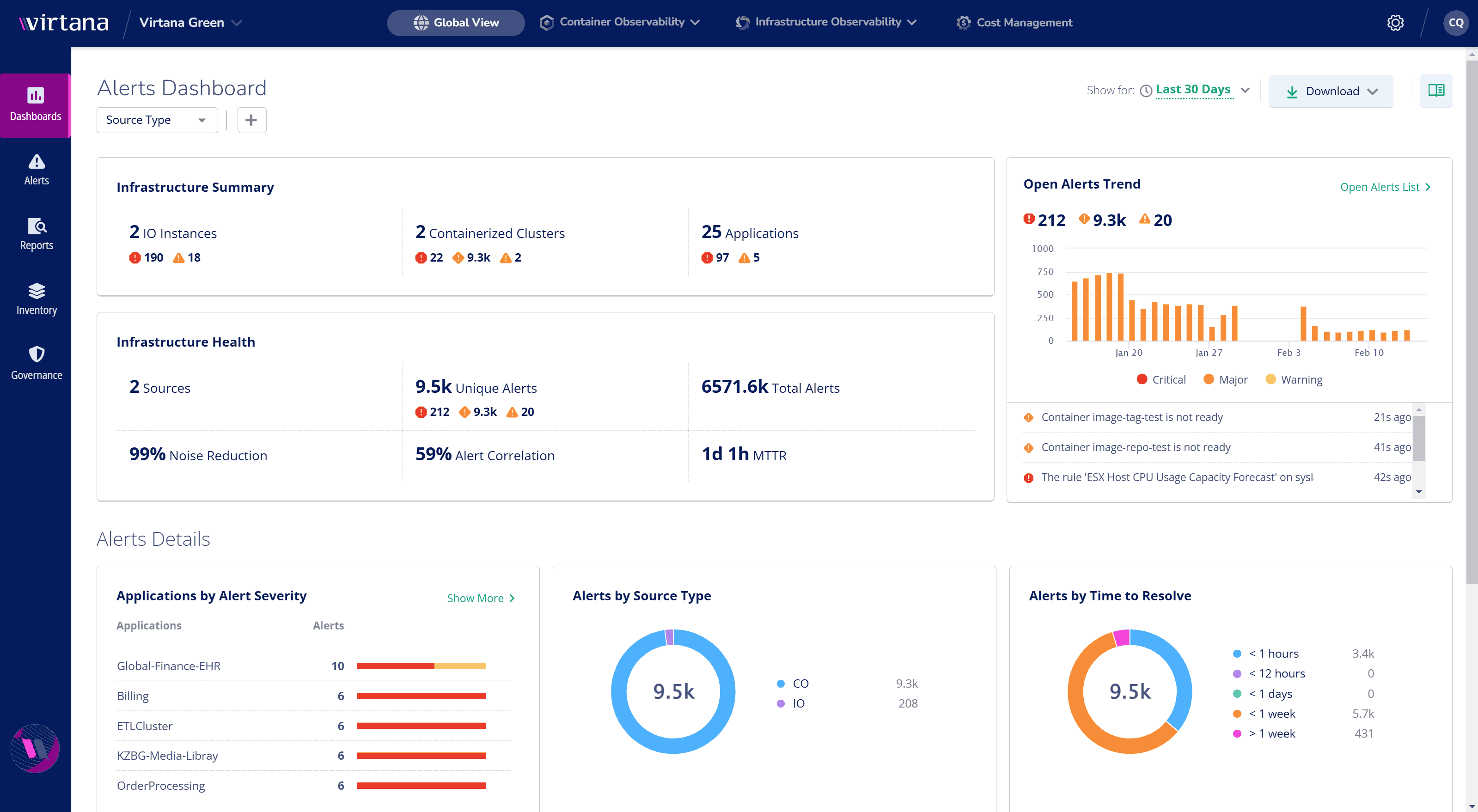
The Solution: Virtana’s Unified OS & Server Observability
Virtana provides a holistic view of server health with host-level metrics, logs, process insights, and automated topology mapping. By combining AI-driven anomaly detection and root cause analysis, we help IT teams optimize performance, reduce alert fatigue, and make data-driven scaling decisions.
Host-Level Metrics & Logs: Complete Server Visibility
Correlate server performance data to detect and resolve issues faster.
- Monitor Resource Usage – Track CPU, memory, and disk utilization in real-time.
- Enhance Troubleshooting – Unify logs and metrics to pinpoint root causes.
- Reduce Downtime – Detect performance degradation before it impacts users.
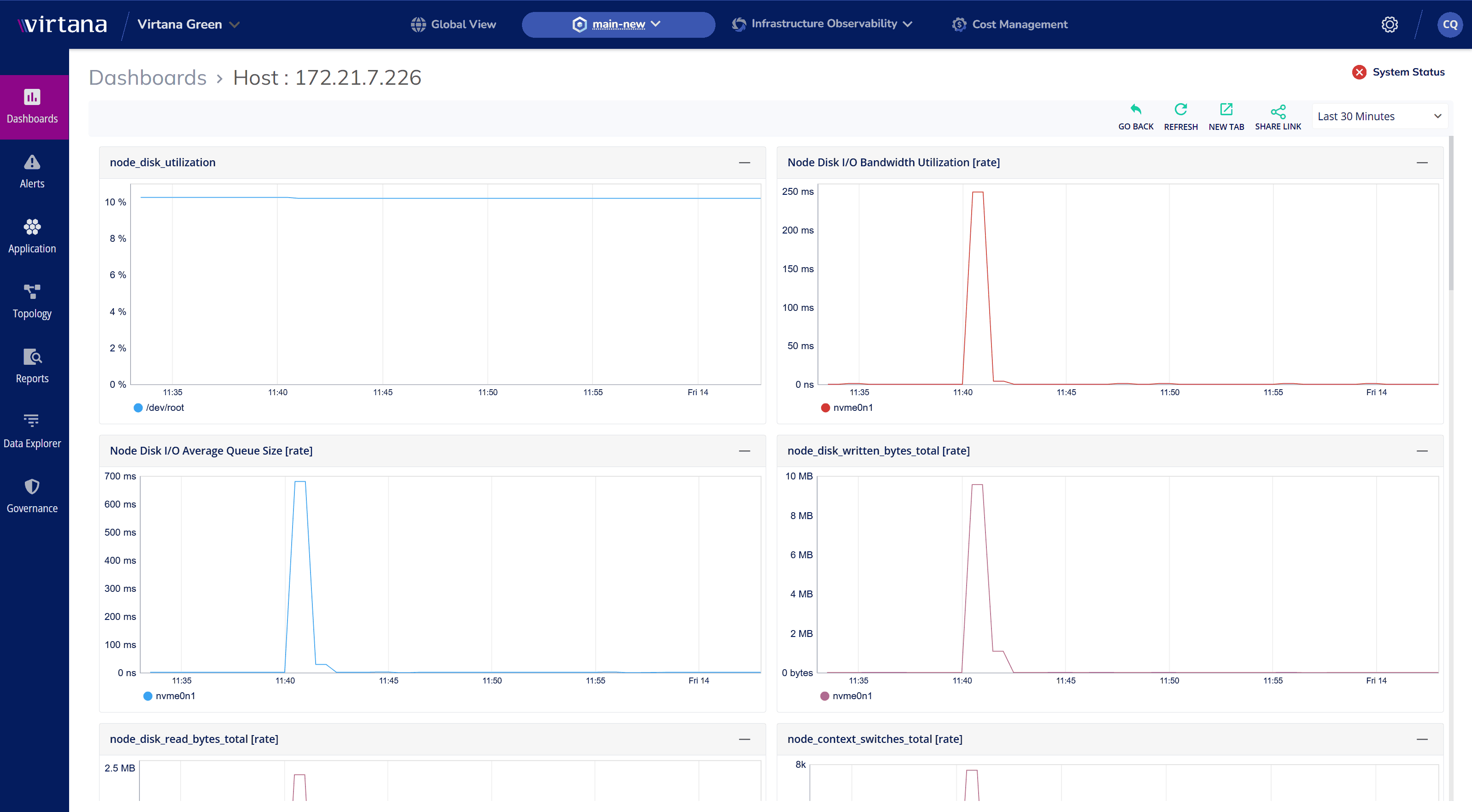
AI-Driven Anomaly Detection: Catch Issues Before They Escalate
Proactively identify deviations from normal system behavior.
- Reduce Alert Fatigue – Intelligent filtering ensures only actionable alerts reach your team.
- Improve Reliability – Detect subtle performance shifts before they cause failures.
- Speed Up RCA – Link anomalies to specific logs and processes for faster resolution.
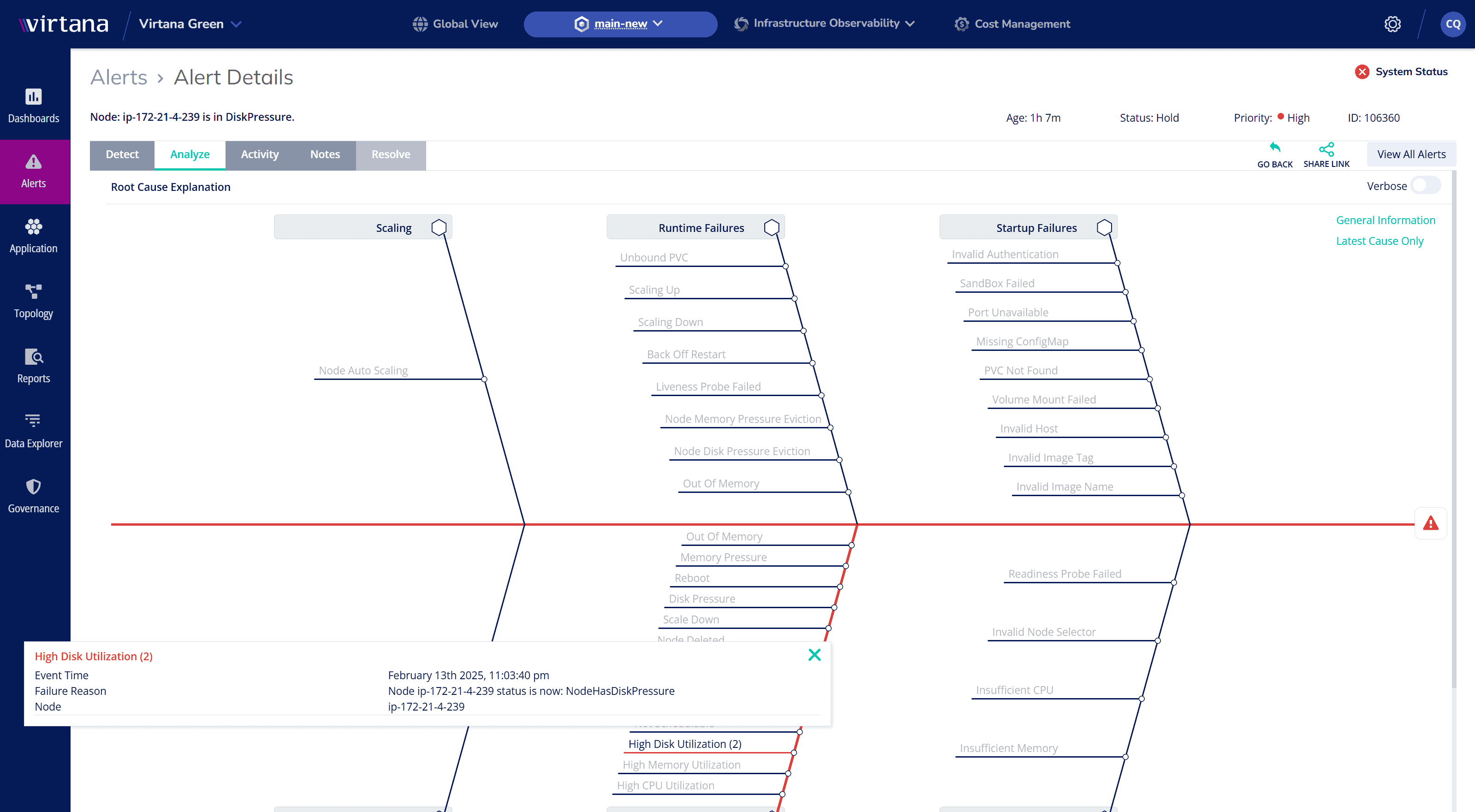
Process-Level Observability: Optimize Workload Performance
Gain deep insights into running applications and server capacity.
- Optimize Resource Allocation – Identify underutilized or overloaded workloads.
- Enhance Application Availability – Ensure critical processes remain responsive.
- Enable Smarter Scaling – Determine when to scale up or out based on actual usage data.
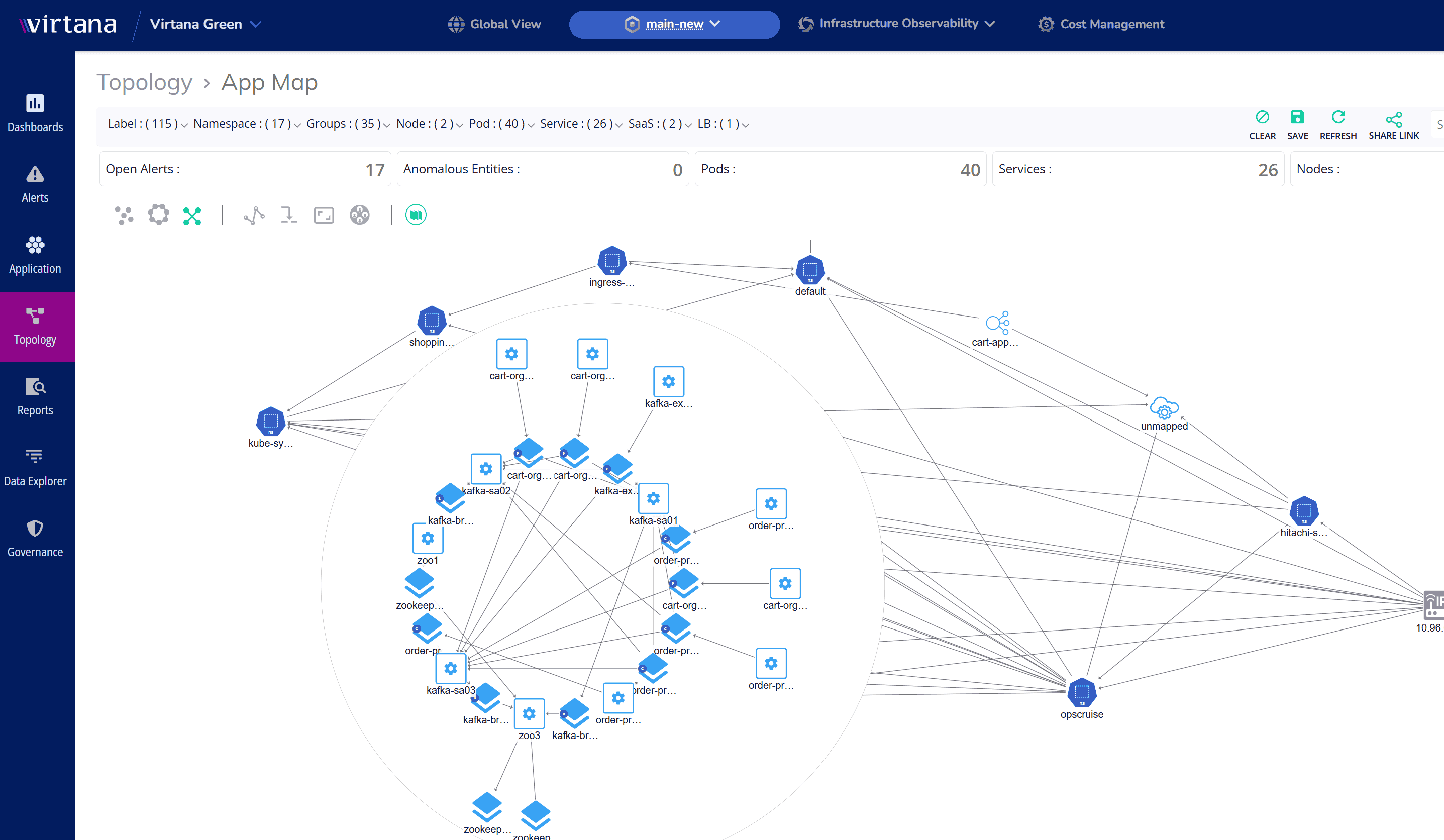
Automated Topology Discovery (Linux Exclusive)
Automatically map process interactions within and beyond the OS.
- Eliminate Manual Mapping – Instantly see how processes communicate across infrastructure.
- Gain Cross-Environment Visibility – Track dependencies across servers, Kubernetes, and the cloud.
- Improve Incident Resolution – Understand how an issue in one process impacts the entire stack.